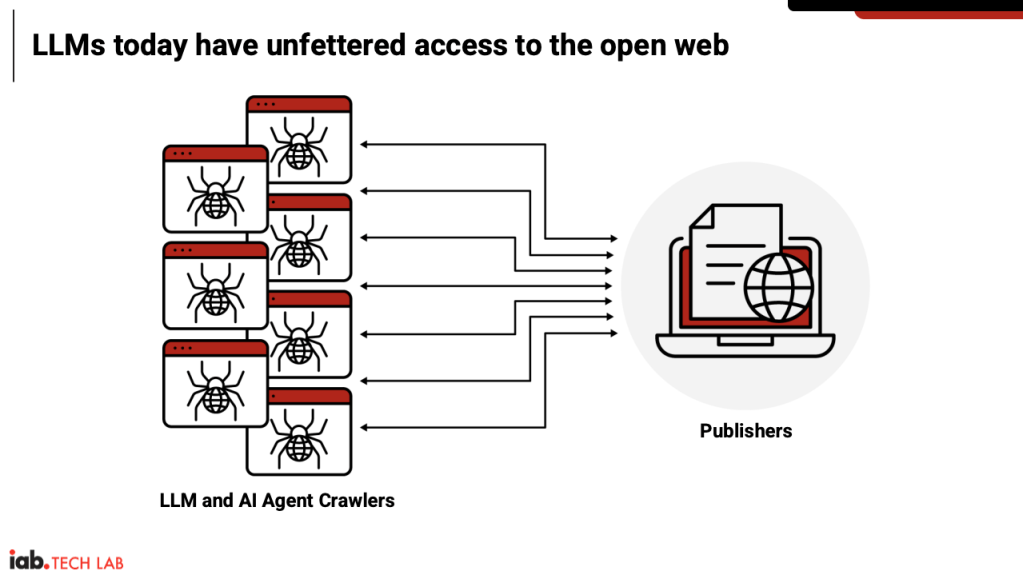
IAB Tech Lab pitches plan to help publishers gain control of LLM scraping

As a Digiday+ member, you were able to access this article early through the Digiday+ Story Preview email. See other exclusives or manage your account.This article was provided as an exclusive preview for Digiday+ members, who were able to access it early. Check out the other features included with Digiday+ to help you stay ahead
The IAB Tech Lab is working to assemble a task force of publishers and compute edge companies to kick off its plan to create a technical framework that helps publishers gain better control of, and be paid for, LLM crawling.
So far, it has roughly a dozen publishers on board for the task force, who will meet for the first workshop in New York City on July 23 (next Wednesday), to discuss next steps for what it has called its LLM Content Ingest API framework. Edge compute company Cloudflare will also attend and speak at the meeting, and the IAB Tech Lab is working to get edge compute company Fastly on board as well, according to CEO Anthony Katsur.
It’s early days, so next steps entail writing the specification — essentially the blueprint or technical guide that will help the different stakeholders (publishers, tech vendors, platforms) build toward the same standard. IAB Tech Lab has an internal draft specification that it’s in the early stages of reviewing with publishers, according to Katsur. Over the last six weeks, it has pitched the overview of this specification (see below) to around 40 publishers globally.
Katsur hopes to have a framework out in the market in the fall.
Naturally, there are some sticky challenges. Getting publishers on board is one thing, but roping in the AI companies to hold up their end is another. Three publishing executives Digiday has spoken to have expressed their concerns that AI companies won’t care to establish compensation or attribution models with this framework.
Katsur is all too aware of the challenges for the LLM Content Ingest API to work; it will need all stakeholders. “I’m skeptical that they’ll [AI platforms] be willing partners to this,” he said.
However, he believes that having publishers and compute edge companies unite on the issue will create infrastructure cost efficiencies for LLM crawlers, which may entice them to take part. “We’re definitely going to be aggressive,” he said, when referencing how they would pitch the final technical framework to AI companies.
Here’s a look at the pitch deck the IAB has presented to publishers.
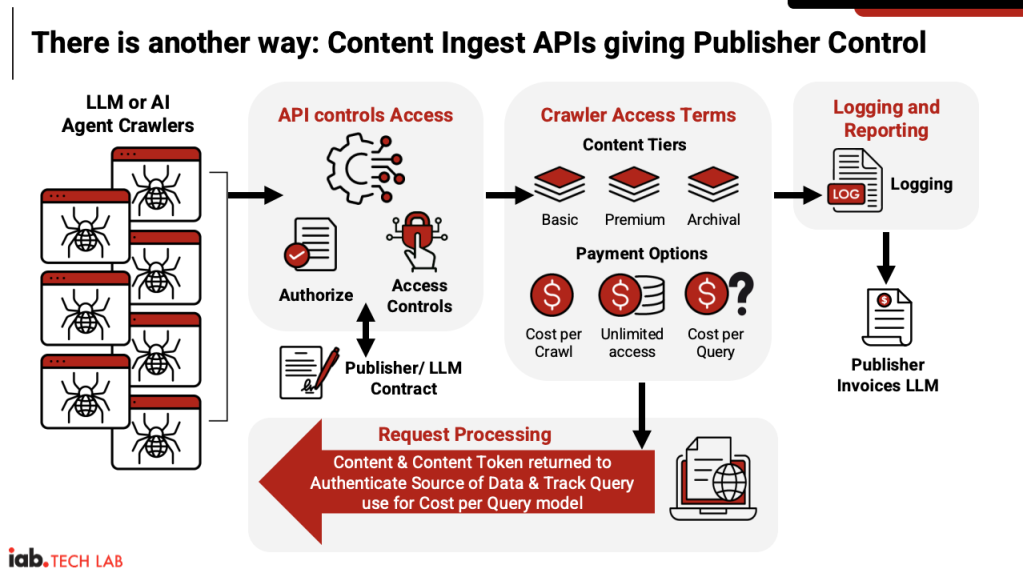
How LLM Content Ingest API will work
First, there needs to be a contract between the LLM provider and the publisher to define what content can be accessed. Only then can the publisher set the crawler terms to reflect that agreement.
Publishers can group their content into tiers: such as basic (daily articles or videos), archival content, and premium content like investigative journalism articles or exclusive interviews.
Then come the payment options: cost-per-crawl, all-you-can-eat unlimited access, and cost-per-query, which is IAB Tech Lab’s preferred model. “We think cost-per-query scales better than cost-per-crawl,” said Katsur. There is a misconception that bots only crawl once; they do in fact return, he stressed, but there are still fewer crawls likely to happen versus queries surfaced in answer engines.
There is also a logging and reporting component, which ensures publishers can invoice the LLM provider correctly. “There can be reconciliation every month in terms of: here’s how many times you crawled me, or here’s how many times I showed up in a query,” said Katsur.
Tokenization to authenticate source – important for brands and publishers
The last step is what IAB Tech Lab refers to as request processing, where it will tokenize the content to ensure the accuracy of the source information, and also show clearly where compensation is needed and to whom. “This is really where cost-per-query becomes feasible – the ability to tokenize content inputs into the LLM, and then every time that shows up in a user query, it’s trackable because you’ve assigned a unique identifier to that particular piece of content if it’s contributed to a query,” added Katsur. “Ostensibly, both the LLM and the publisher should be able to track that.”
For Katsur, tokenizing content is especially important because it helps identify the original source within the “contextual stew” of AI-generated answers, which are typically synthesized from multiple publisher sites.
Brands are also concerned about the likelihood of their products being misrepresented in queries, noted Katsur. CPG and auto manufacturer brands he has spoken to have noticed confusing or error-prone queries related to their products, raising concerns about missed sales opportunities or the loss of existing or new customers.
If AI answer engines draw on content from three different publishers to generate a response, then tokenizing the articles could help identify the contributions, making it easy to split the payment between them.
Elephant in the room: enforcement
While publishers welcome any efforts to assist with creating a more sustainable AI-driven model for publishers, where their content isn’t ripped off, there is a healthy level of skepticism over just how an API like LLM Content Ingest can truly prevent scraping. Their view: it needs to be more robust than the robots.txt, which so far has been easy to ignore or to game.
Katsur stressed that there are some nefraious tactics being used by some LLM crawlers, who will simply use a different, undisclosed crawler if their original one gets listed in robots.txt. For this proposed standard to work, publishers need to take a hard line on all crawling, he added.
“To enforce this model, you have to have a very strong fence,” said Katsur. “And all it’s going to take is one weak link in the fence, of one publisher saying, ok you can keep crawling.”
He said publishers need to form a coalition to take a clear stance: the crawling has to stop. This is where the edge compute platforms come in. “We’re confident Cloudflare and Fastly will be part of the task force with the publishers. They’re the ones in the best position to stop the crawling, and the ones best equipped to detect crawlers that don’t obey robots.txt.”
There is also some hope that the AI companies will need to play ball, once the outcome of the ongoing publisher lawsuits – like those led by the New York Times and Ziff Davis – (should they favor the publishers) are confirmed. Katsur also believes there are a couple of basic AI laws regulators should make, that wouldn’t quash AI innovation: declare your crawler and fines robots.txt is flouted.
“The challenge we face is that this is happening so fast. When we talk with publishers we’re hearing traffic declines of 30%-60% [in the US] and that’s unsustainable. And this is only the tip of the iceberg in terms of LLMs and zero-click search… We have to be really aggressive as an industry in tackling it.”









More in Media

People Inc.’s Jon Roberts on the AI licensing boom – and the revenue lag
People Inc’s Jon Roberts discusses the boom in AI content licensing marketplaces — and the revenue that could materialize for publishers.

YouTube is building infrastructure for the full creator-brand partnership life cycle
YouTube’s Gemini-powered Creator Partnerships promises to alleviate pain points in the influencer marketing pipeline.

Joint signings highlight growing convergence between creator and Hollywood agencies
What a spate of joint signings between Reign Maker Group and Paradigm Talent Agency tells us about diversifying talent and owning media in the creator economy.