
This is the latest in a series of articles that explain, in plain English, new technology tools and platforms that are changing the face of digital media. See other entries here.
“Error 404” pages have become a common part of the Web experience. But while most people have shrugged off broken links as a necessary nuisance, some see them as a problem that threatens the ability for people to freely access information online.
Academia has taken note. Last week, Harvard’s Berkman Center released Amber, a WordPress and Drupal plugin designed to help websites keep linked content accessible by storing copies of Web pages. If a linked page goes down, Amber serves the cached alternative. Here’s a primer on link rot and why it’s a problem many see as worth fixing.
So what is link rot, exactly?
It’s not too complicated. Link rot is a somewhat dramatic name for broken links. It’s a vital topic for anyone concerned with the perseveration of content on the Web.
OK, so “404” errors. What causes them?
Blame technology, or more likely, human error. Link rot can happen when a site migrates to a new CMS or link structure, which can break links to old pages. Sometimes sites go offline completely, taking all of their links with them. The most common cause of link rot, though, is human intervention. Links break on the Web because sites take content down. BuzzFeed, to use a recent example, deleted thousands of posts in 2014 because they no longer reflected its updated editorial standards. That’s just one prominent example, but the problem is more widespread.
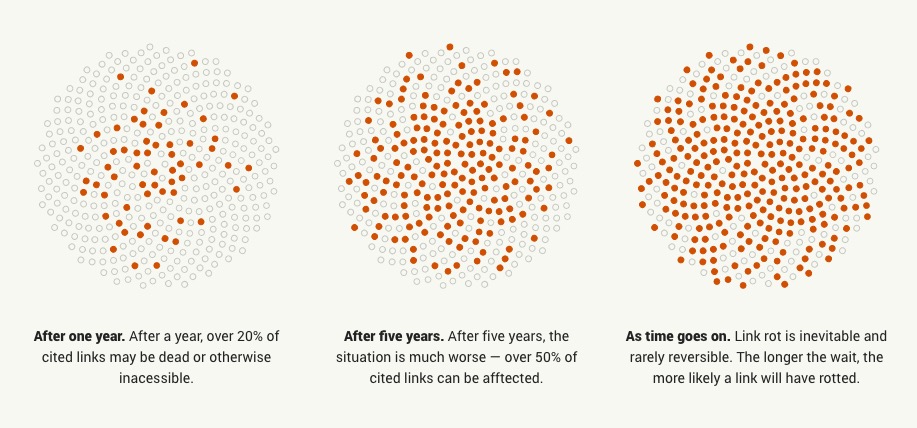
So why are academics so obsessed with this?
Academia, at its core, is built on citations. When building a case, lawyers and academics have to not only show their own work but be able to show and link to previously published work that supports their conclusions. But doing so is harder to do on the Web when websites are constantly changing and when it’s almost effortless to pull content down. It’s enough to make an academic long for print, where this problem doesn’t exist.
I still don’t get why this is an issue. It seems tiny. Give me some numbers.
It’s not a tiny problem at all. Wikipedia, for example, says that over a 130,000 its entries link to pages that are no longer there. Likewise, a 2013 Harvard study found that 49 percent of the hyperlinks in Supreme Court decisions don’t work. NPR called link rot a “virtual epidemic” in 2014.
“Epidemic” might be overstating it, but I get your point. This is the part where I ask about solutions.
There’s been no shortage of attempted fixes to the link rot problem. The one most people are probably most familiar with is the Internet Archive Wayback Machine, which has achieved 464 billion Web pages over the past 20 years. Other attempts include the academia-focused Perma and the aforementioned Amber.






More in Media

With Firefly Image 3, Adobe aims to integrate more AI tools for various apps
New tools let people make images in seconds, create image backgrounds, replacing parts of an image and use reference images to create with AI.

Publishers revamp their newsletter offerings to engage audiences amid threat of AI and declining referral traffic
Publishers like Axios, Eater, the Guardian, theSkimm and Snopes are either growing or revamping their newsletter offerings to engage audiences as a wave of generative AI advancements increases the need for original content and referral traffic declines push publishers to find alternative ways to reach readers.

The Guardian US is starting its pursuit of political ad dollars
The Guardian US is entering the race for political ad dollars.